
Let's Start with 'Why?'
Most of the preprocessing phase of pipelines has the complexity of taking the unstructured data or the Dark Data like text, Tables, Image, etc, and turning into the structured data which usually takes months or years and to build ML models further.Before building an ML model over the extracted data, we need to Hand label it, those are called Gold Labels. If we look from Today's Machine Learning pipeline at a high level this explicitly says that people spent most of the time on creating the Training Dataset and little hustle over Feature Engineering as Deep Learning makes it easy, the crucial part of creating a Training data set is labeling that data points correctly, because the performance of the end model totally depends on how well it trained with correct labels. Now, the question is can we hasten up the process of labeling using any Framework ?, This is where Snorkel began to accelerate Data Building and Managing, not only labeling, snorkel has many other features that make the bottlenecks unclogged.Snorkel: A framework for Rapidly Generating Training Data with Weak Supervision.
Weak Supervision
By eliminating the Hand labeling process, Now we can programmatically generate labels with external Domain knowledge or any patterns. This results in low-quality lables[Weak labels] more efficiently, which means Weak labels are intended to decrease the cost and increase efficiency. Using noisy, imprecise sources for building a large amount of training data in supervised learning is called Weak Supervision. One of the famous methodologies of weak labeling is Distant supervision. To reiterate Snorkel is an open-source system for quickly assembling training data through weak supervision.
What Snorkel can do?
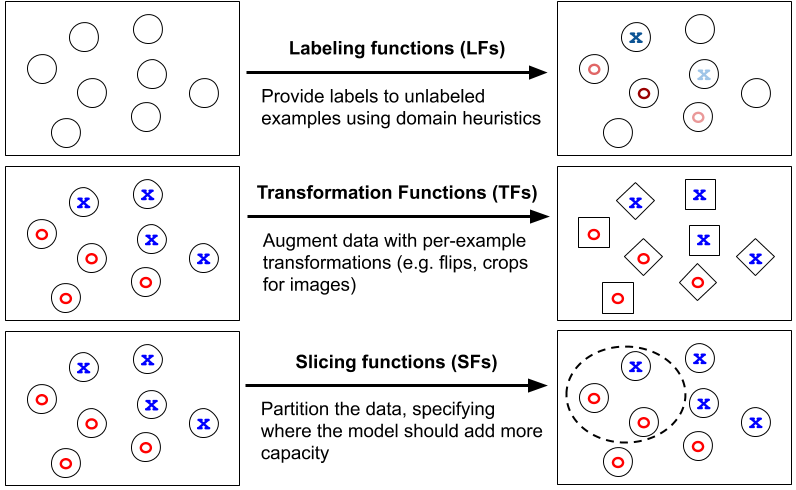
Snorkel currently has three features for creating and handling training data sets.
- Data Labeling: Assigning a value to each data point based on Heruristc, Distant Supervision Techniques, etc.,
- Data Transformation: Converting existing data from one format to another or modifying the data which doesn't affect actual labels. e.g: rotating an image in different angles, etc.,
- Data Slicing: Segmenting a data set into required subsets for different purposes like improving model perfomance.
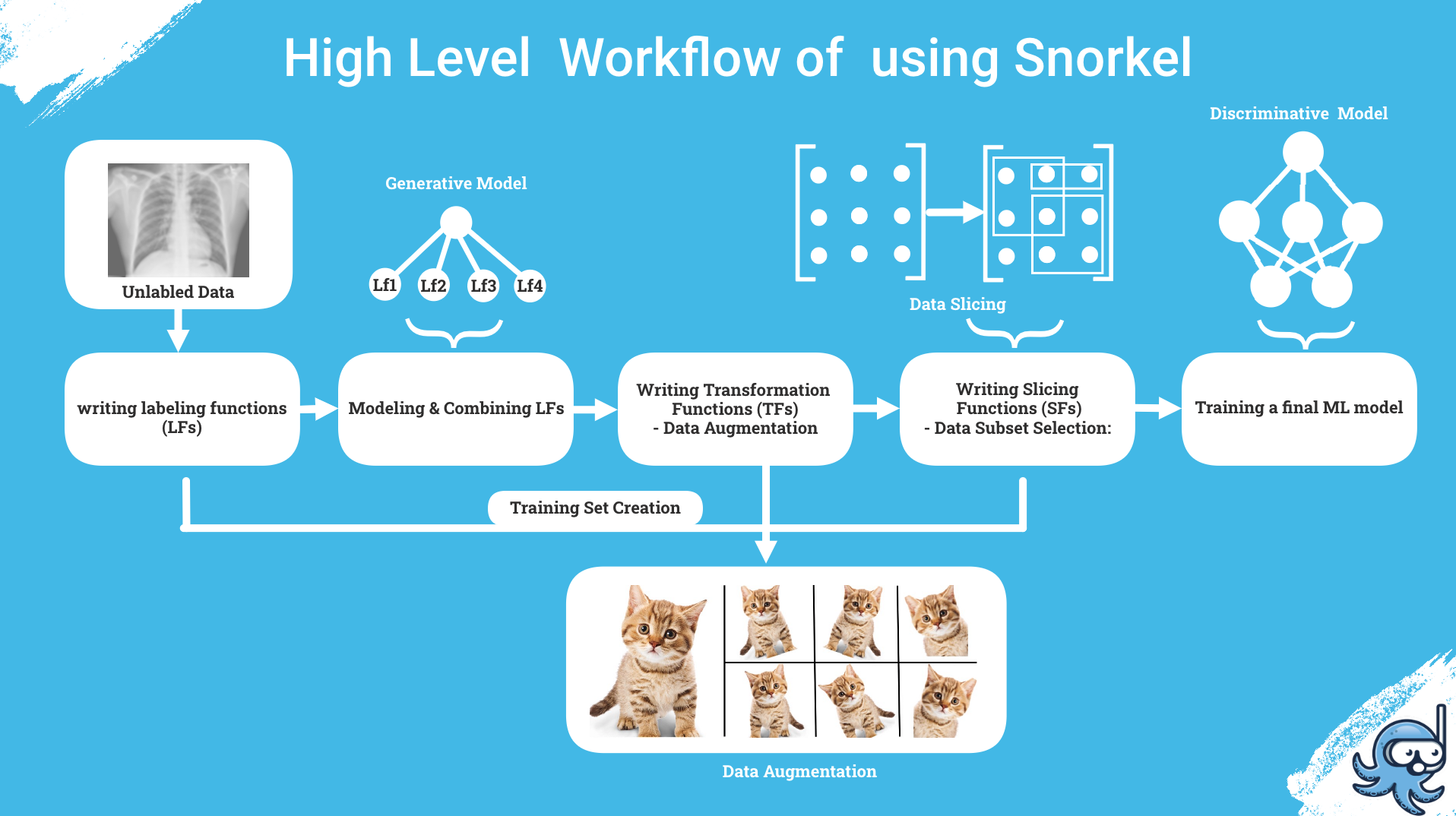
How Snorkel does it?
The Hight level Architecture of Snorkel's Workflow consist of Five Steps:
- Writing Labeling Functions. (LFs)
- Modeling and Combining Labeling Functions.
- Writing Transformation Functions for perfoming Data Augmentation.
- Writing Slicing Functions for Subset selection.
- Training a final ML Model.
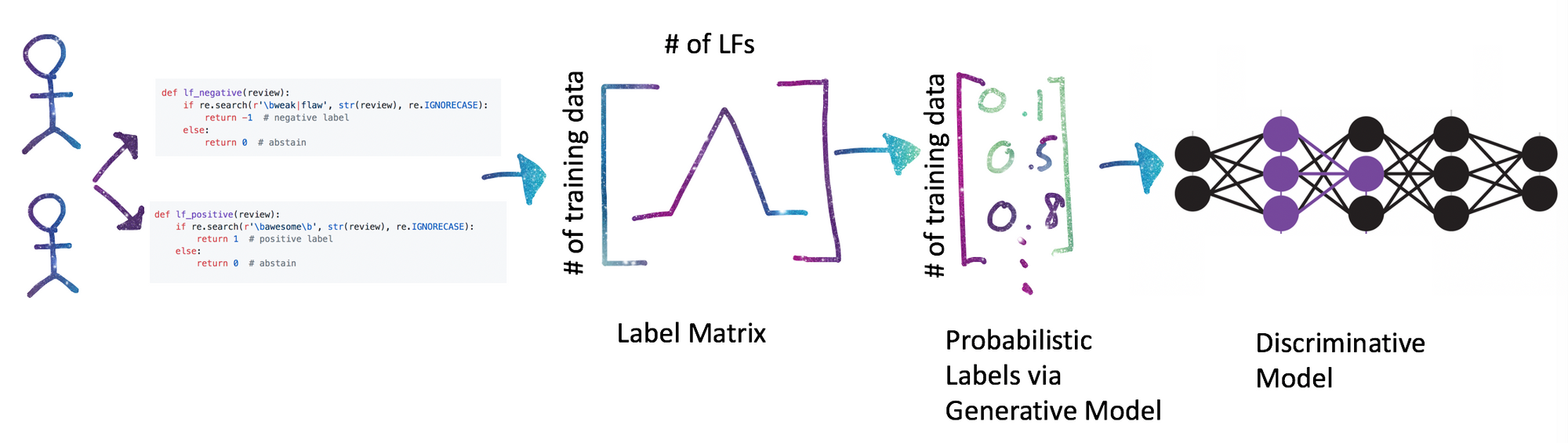
Following up these, the takeaway parts of Snorkel is its ability to use labels from different Weak Supervision sources and the set of all labeling functions are modeled by combining and applying a Generative Model [LabelModel] that generates a weak set of labels. Along with that, the system can output Probablistic labels that can be used to train various Classifiers, which indeed generalizes noise labels.
Data Labeling
There are few diffent ways that you would totally turn into weak suprevision by using a python decorator labeling_function() or a python class LabelingFunction.
- Heuristics: applying set of conditions by a pattern, ex: using regular expressions
- Third party Models: Using an exisiting Model to perfome labeling.
- Distant Supervision: Using Existing ground truth data that imprecisely fits in, [External Knowledge Bases].
Let's suppose, we have three different labeling functios are written using conditional pattern and Regular expresions. Expample taken form Snorkel-tutorials.
@labeling_function()
def check(x):
return SPAM if "check" in x.text.lower() else ABSTAIN
@labeling_function()
def check_out(x):
return SPAM if "check out" in x.text.lower() else ABSTAIN
# with Regex
@labeling_function()
def regex_check_out(x):
return SPAM if re.search(r"check.*out", x.text, flags=re.I) else ABSTAINNow, these labeling functions can label in their own way, which is completely independent, the lables would varry.
Applying LFs
Snorkel provides Labeling Functions applier for Pandas DataFrames, we can use PandasLFApplier(lfs) which takes a list of labeling functions and return Label Matrix in which each columns represents the outputs of each labeling function in the input list.
lfs = [check_out, check, regex_check_out]
applier = PandasLFApplier(lfs=lfs)
L_train = applier.apply(df=df_train)
For understanding the perfomance and analysing multiple labeling functions let's burst some terminologeis.
- Polarity: The set of unique labels that LF outputs
- Coverage: The fraction of the dataset the LF labels
- Overlaps: The fraction of the dataset where the one LF and atleast one other LF label same.
- Conflicts: The fraction of the dataset where one LF and at least one other LF label and disagree
- Correct: The number of data points that the LF labels correctly (if gold labels are provided)
- Incorrect: The number of data points that this LF labels incorrectly (if gold labels are provided)
- Empirical Accuracy: The empirical accuracy of the LF (if gold labels are available)
When we apply LFAnalysis[Labeling Functions Analysis] utility, it results the above metrics for each labeling function.
lfs = [check, check_out, regex_check_out]
LFAnalysis(L=L_train, lfs=lfs).lf_summary(Y=Y_dev)

After done writing Labeling Functions, and the L_Train has respective columns that represents the corrosponding outputs, our goal is to consie and generate one standard column which has noise-aware probablistic label per data that can be appended to unlabeled dataset for futher training purpose.
This process of generating the final label column can be done in few approaches. We can take a Majority vote from the L_train for each data point and result a single value.
from snorkel.labeling import MajorityLabelVoter
majority_model = MajorityLabelVoter()
preds_train = majority_model.predict(L=L_train)
One other approch is Snorkel can train a Label Model that takes advange of conflicts between all Labeling Functions and estimate their accuracy. This model with produce a singel set of noise-aware labels, which are porbablistic [Confident-Weighted]. We now can use the resulting probablistic label values to train various classifiers.
We can use techniques like Logistic Regression, SVM, LSTM at this stage. The discriminative model learn feature representation of our labelling functions and this makes it better able to generalize to unseen data. This will increase the recall and produces final output.
from snorkel.labeling import LabelModel
label_model = LabelModel(cardinality=2, verbose=True)
label_model.fit(L_train=L_train, n_epochs=500, lr=0.001, log_freq=100, seed=123)
preds_train = label_model.predict(L=L_train)
Data Transformation
Transformation is a technique of Data Augmentation, a proper data augmentation certainly boosts up the model performance. Computer vision is the area of work where Data augmentation is used extensively, an Image can be augmented by rotating, flipping or adding filters, etc. When it befalls to the part of Text the complexity of applying Augmentation goes up. A simple example of transforming a text is by replacing the existing words in the document by its synonyms. But not every word can be replaceable such as a, an, the, etc.
When we ask what that really makes Data Transformation a big difference is the More the data we have, the better the model performs. As we transform a data point in different ways, we certainly do not affect the label so it explicitly generates data that could most benefit the training phase.

Writing Transformation Functions
Snorkel provides a python decorator `transformation_function` which takes a single data point and returns the transformed version of it. If the data transformation isn't done it returns `None`, If all the TFs applied to a data point return None, the data point won't be included in the augmented dataset when we apply our TFs below.
@transformation_function(pre=[spacy])
def change_person(x):
person_names = [ent.text for ent in x.doc.ents if ent.label_ == "PERSON"]
# If there is at least one person name, replace a random one. Else return None.
if person_names:
name_to_replace = np.random.choice(person_names)
replacement_name = np.random.choice(replacement_names)
x.text = x.text.replace(name_to_replace, replacement_name)
return xApplying Transformation Functions.
A little similar approach as applying labeling functions, Snorkel provides a specific class for Pandas DataFrame `PandasTFApplier`, where the PandasTFApplier takes list of transformation functions and a Policy, a Policy is used to determine what sequence of Transformation functions to apply, here we use `mean_field_policy`, which allows specifying a sampling distribution for the Transformation Functions.
from snorkel.augmentation import PandasTFApplier
tfs = [change_person, swap_adjectives, replace_verb_with_synonym, replace_noun_with_synonym, replace_adjective_with_synonym]
tf_applier = PandasTFApplier(tfs, mean_field_policy)
df_train_augmented = tf_applier.apply(df_train)
Y_train_augmented = df_train_augmented["label"].valuesReference:
Snorkel Tutorials; snorkel.org; Snorkel a weak supervision systerm; Introducing Snorkel; Snorkel-June-2019-workshop;
My Exprience at Imaginea Labs.
A short period of time may not give you much experience, but it leaves you with constructive insights that you could transform the way you admire. - tejakummarikuntla.
I'm the youngest friend to everyone in the team not only in age but also in thoughts and actions ;p. I always feel that the connections and habits you build will build you back and I tried every day doing it my best. I spent most of my time to Unlearn and relearn in the other dimension that could easily create vivid impressions over the journey and this is the endgame of my Internship journey[24/01/2020].
TL;DR
Here are a few takeaways that I could only mention by writing. As there are many (intuitions/Familirites) that I couldn't express in words.
Sri would be probably chuckling when he notices that I tried using Intuition and Familiarity interchangeably [Familiarity Breeds Intution]
- Constructive learning approach.
- Learning how to learn.
- Art of not negotiating peculiar advice.
- Aligning the mathematical thinking with programmatical implementation.
- Unlearning.
- Lucid approach to understanding a research paper.
- It's not about how much you know, it's all about what you can devise with it.
- Tracking the new learning by logging in Latex or Markdown.[Zotero]
- You can only know the curx when you keep questioning 'Why?'
- Mathematical bonding not only with life but also with Music and Art [Godel, Escher, Bach]
- You can only Enjoy working when you see a purpose in it.
- Healthy relations will amplify performance.
- When you start expressing, you will start noticing different results.
- Laughing for lame jokes isn't a sin, coz I do a lot ;p [Not lame jokes ] I know it's very lame ;p.
I've updated my technical progess at GitHub [Never missed a day to commit :D], feel free to check out and keep in touch @ LinkedIn, Instagram.
Thank you for all my amazing mentors❤️:
Arun Edwin, Vikash, Sachin, Ebby, Vivek, Rehan, Vishwas, Nimmy, Vijay, Swamy, Kripa, Arthy, Sri, Hari.

Originally Published at: Imaginea Labs
